RESTFul Web Services with Spring Boot
To understand RESTful API or RESTful web services, You first need to understand what an API is. API(Application Programming Interface) is a software/application/library/mechanism that helps one program to communicate with another. The most widely used API types are web-APIs or web services. In this type, a client sends an HTTP request, and the server sends back an HTTP response.
For instance, if you are on a banking site, and you want to see the balance, The browser sends a request to the bank servers and gets a response with relevant account details.
REpresentational State Transfer (REST) is a set of software design guidelines to develop applications that interact over HTTP. If a web API follows REST’s architectural constraints, then it can be called a RESTful API.
Properties of a RESTful Web Service
The reason why RESTful APIs exist is because of its promised Architectural Properties. If implemented correctly, a RESTful web service would demonstrate properties such as
- performance
- scalability
- simplicity
- modifiability
- visibility
- portability
- reliability.
By definition, A Web-Service should comply with the following architectural constraints to become a RESTFul web service or RESTful API. I will go through them one by one and what they mean and how they help in developing applications that couples loosely over HTTP.
Client-Server Model
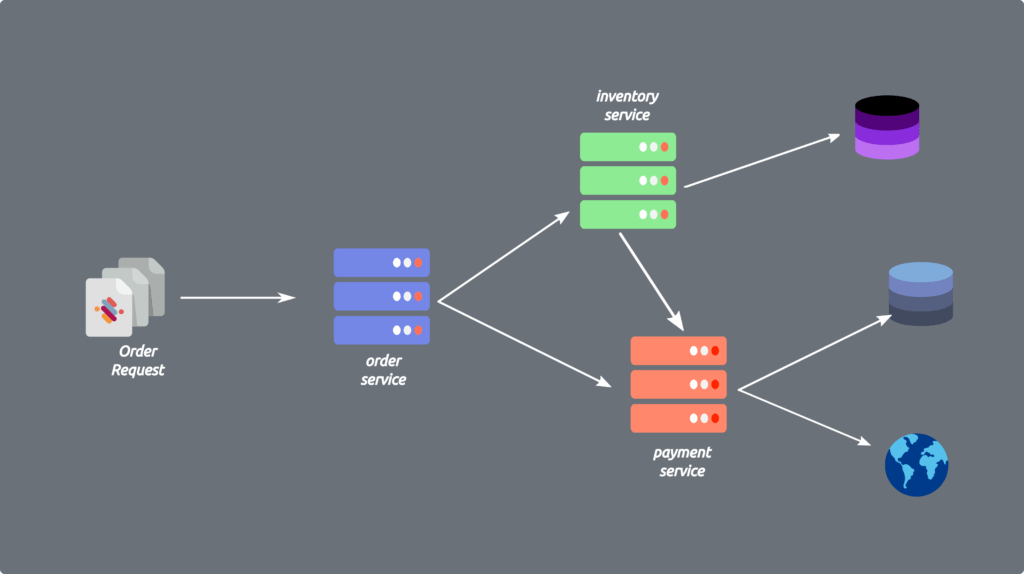
The main reason behind this constraint in RESTFul web services is the separation of concerns. For example, in a shopping site, moving account-related components away from inventory and orders is a good thing because we can extend each of these components individually. The Order component can act as a client and perform an API request to Payment and Inventory web services if needed. It also improves scalability as each separate component can evolve independently.
Stateless systems
Take a look at this sample code.
@GetMapping("/nextPage")
List<Orders> getNextOrders() {
currentPage = currentPage +1 ;
return getPage(currentPage);
}Code language: PHP (php)The problem with this code is that the server maintains the state of what the client wants to do. And this state is maintained between requests. This is what we call stateful systems. These type of implementations may seem comfortable at first. Things will become ugly as the client now needs to know for sure which page it will get. This is why stateless systems are far efficient. This is why restful web services try to avoid the state altogether.
A system is stateless when the server doesn’t maintain any state between each requests. Take a look at the below code for the same problem we tried to solve before.
@GetMapping("/pages/{pageNumber}")
List<Orders> getNextOrders(@PathVariable Integer pageNum) {
return getPage(pageNum);
}Code language: CSS (css)With this implementation, the server doesn’t keep the current page number. The client gets to have the control of which page it wants to read.
Cacheability
As REST believes in HTTP concepts of the World Wide Web, clients and intermediaries are allowed to cache responses when possible. The servers and clients must provide enough hints to let the other party know if they support caching. In an ideal REST service, the caching partially or fully eliminate client-server interactions and thus improves scalability and performance.
Layered System using RESTful web services
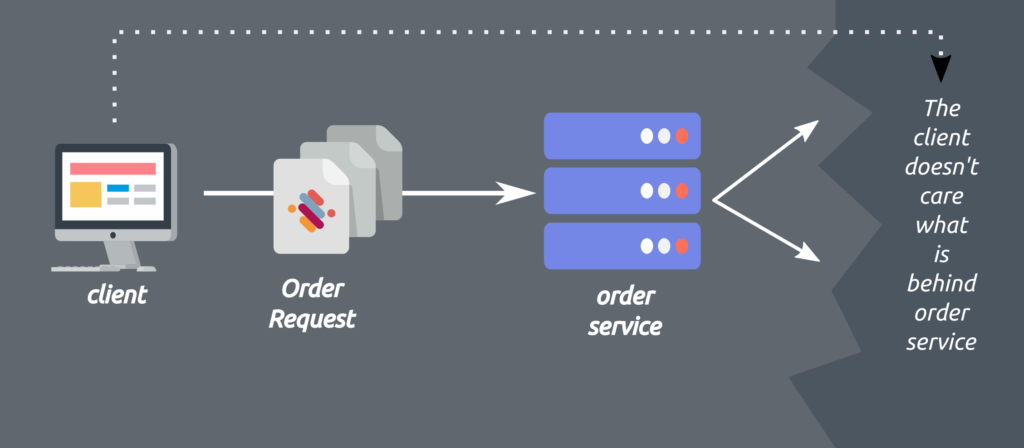
A Client may not have to know what is behind the server it is requesting resources. A client may call order service and order service may internally query stock and price details from another service. This approach further enables the separation of concerns and thus letting each component evolve individually.
Code on demand
This is an optional constraint dictated by the RESTful web service specification. In a web API request, the request and responses are usually JSON or XML. But when you have to and if the client allows you may serve executable content as responses, for example, JSONP, APPLETS etc.
Uniform interface
For a web service, the client can be of any form. It can be a mobile app, a website, a smart device or even another service. With different type of clients, the code can become clumsy once we start writing platform-specific code. REST wants to avoid these type of situations. A RESTful system should always have a single interface for all type of clients. No matter which type of client makes requests, the server should behave the same way, This is what we call a uniform interface.
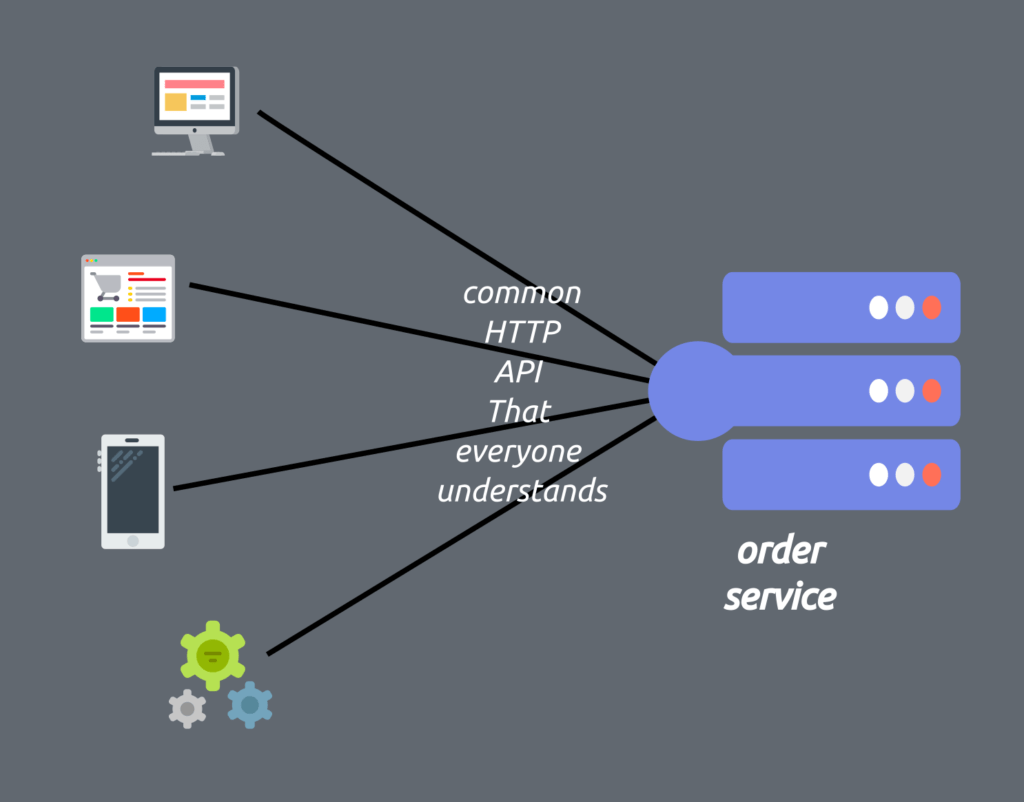
Uniform interface is the core constraint for a service to be RESTful. This constraint dictates how each component in RESTful systems should communicate with each other. The primary goal of this constraint is to provide a set of sub constraints that would streamline how client and servers can agree on the following.
- Where to look for resources
- How to look for resources
- How to agree to a format that client and server understand
- And Is all the above implemented throughout the system
We will see about these sub constraints in details.
Resource identification requests
A resource in RESTFul Web Service is a similar Object in Object-Oriented Programming or is like an Entity in a Database. It could be a web page, A single Object or an Entity. It may even represent any arbitrary content. Because of this nature, We need to address these unique resources, REST design principle advises us to use URIs.
By using URLs, we can arrange the resources in a hierarchical order. Let’s take an example. In an order management system, The following list will explain how we can represent the resources as URLs.
/ordersall orders./orders/{orderId}order with specific order number/orders/{orderId}/itemsall items in that order/orders/{orderId}/items/{itemId}a single item in an order/orders/{orderId}/accountwhich account ordered it./accounts/list of all accounts in the system/accounts/{accountId}specific account
The actual content of these URIs should provide enough information for the client to perform the necessary tasks. For instance, the client gets the data of the account when looking at the order. This way client can go back to the list of accounts and find relevant orders if they want to. Once we embrace this logic, REST APIs become easier to understand.
Sometimes, You may not be able to give out all the information in a RESTful service. For example, child objects may have too much information That would increase the response size. The client should be able to follow the URIs to get the necessary information. This type of implementation is called HATEOAS(Hypertext As The Engine Of Application State).
Resource manipulation through representations
A client can perform CRUD operations on a resource identified by a URI(if the client has enough access). The good thing here is that URI can be an URL and thus we can map each crud operations into an HTTP verb.
| HTTP Method | Intended operation on a URI |
|---|---|
| GET | Read a resource pointed by the URI |
| POST | Create a resource at the pointed URI. Ideal implementation should return a URI of the created resource |
| PUT | Replace all the representations of the member resource or create the member resource if it does not exist, with the content in the request body. |
| PATCH | Update all the representations of the member resource, or may create the member resource if it does not exist, using the instructions in the request body. |
| DELETE | Delete all the representations of the member resource |
Self-descriptive messages
Each operation we spoke about earlier results is a response from the server. In some cases, the server will send responses. In other cases, there may be status messages. As we use HTTP for communication and HTTP by default comes with a variety of client-server status codes, we don’t have to invent new status messages or codes. For example,
HTTP 2xxmeans success.HTTP 3xxmay represent redirects or Cache related indicationsHTTP 4xxmeans that the client didn’t send an appropriate request.HTTP 5xxmean the server is either not in an accepting state or could not process the request.
Hypermedia references (HATEOAS) for Web service endpoints
In response to one Resource, we may not represent all of its child/parent Resources. In these cases, We need to point to the right resources within our resource response from the server. But we solved this problem already, with URIs. Each resource response may contain URIs of their related Resources, Following these Resource URIs will give the client to explore if they want to. These are called Hyper-Media-Driven outputs. And the representation is called HATEOAS (Hypertext As The Engine Of Application State). For example, take this output JSON for Order resource.
{
"orderId": 1,
"total": 54.99,
"_links": {
"self": {
"href": "http://localhost:8080/orders/1"
},
"account": {
"href": "http://localhost:8080/accounts/2"
},
"items": {
"href": "http://localhost:8080/orders/1/items"
}
}
}Code language: JSON / JSON with Comments (json)Here the items field of Order is a collection of Items. Thus it would have taken a large number of bytes in the response. If the client wants that information, It can always navigate to http://localhost:8080/orders/1/items. Same for account field which is related to this specific order.
Advantages of restful web services.
- By the nature of being stateless, The restful services are easier to scale up and down.
- The components are split based on logical layers. So upgrading separate components can be easier. This is why most of the micro-services go for a RESTful approach.
- Definitive operation instructions. As we saw earlier, each HTTP method is synonymous with an HTTP verb. This way no complex API documentation is needed. For example, A developer would infer that he needs to Call
HTTP.DELETEmethod if he needs to erase a resource. - Let’s be honest. Naming an API URL can be brain-numbing. Instead of choosing between,
/getOrdersForAccountor/accountOrders, We could simply name using the hierarchical naming convention/account/orders. This is easier and less ambiguous to understand. - With proper caching, The server load is reduced drastically. The benefit of not storing states increases the server’s performance.
- The client has most of the control.
For you to learn, We have a variety of restful examples in our SpringHow GitHub organization. Feel free to try them out.
If you liked this article, You may find the following articles interesting.